公司殷亚凤老师课题组近期在长手语视频分割领域取得新进展:首次定义了长手语视频自动分割任务,并提出了一种基于边界学习的句子级手语视频分割技术。该技术能够将连续的长手语视频自动分割为多个句子级视频片段,缓解现有句子级手语数据集规模有限、标注成本高的问题,并推动长手语视频理解等相关领域的发展。

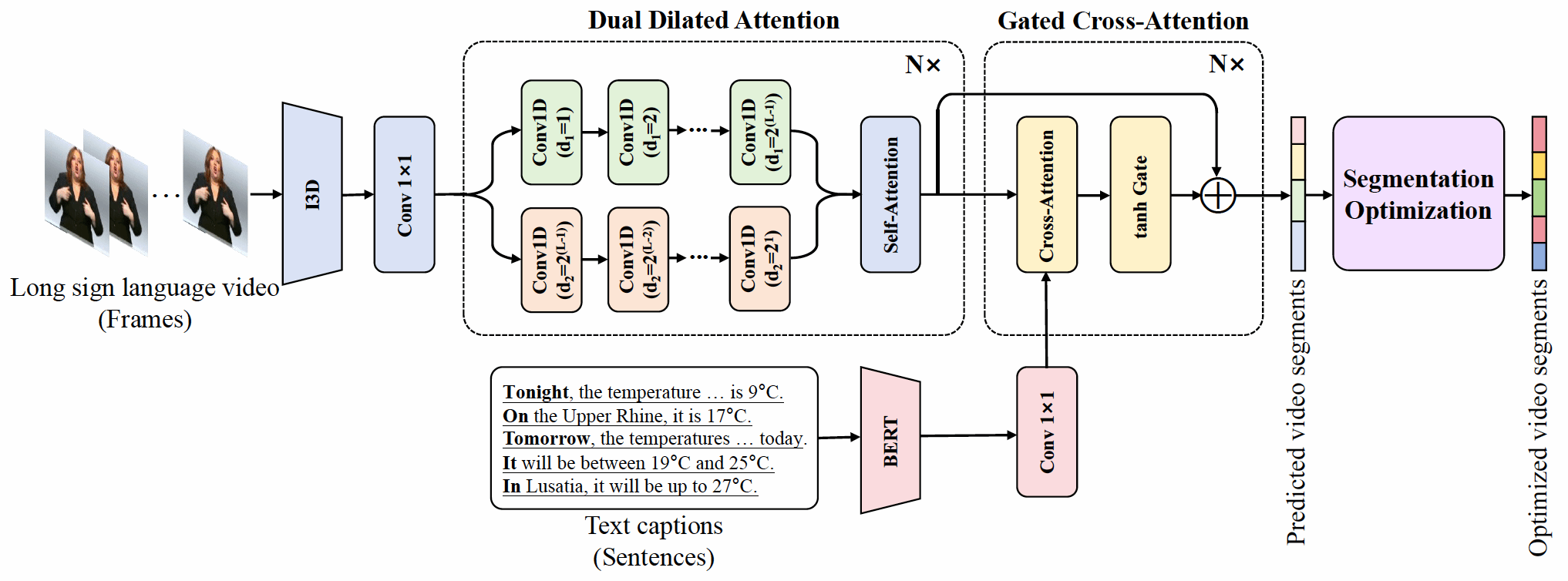
Sentence-level Segmentation for Long Sign Language Videos with Captions. 手语理解研究通常依赖于句子级样本,但由于标注成本高,现有数据集往往规模有限,难以支撑更大范围的研究与应用。为此,该研究工作首次定义了长手语视频自动分割任务,旨在将长时间手语视频自动分割为句子级视频片段,从而构建句子级视频样本,推动手语理解领域的研究。然而,长手语视频中往往缺乏显著的句子级转换标志,并且分割任务中常见的过分割和欠分割问题,使得手语分割任务面临诸多挑战。为此,该研究工作提出了一种基于边界学习的句子级手语视频分割技术。首先,提出多帧边界标注策略,将句子边界检测形式化为逐帧分类任务,解决了边界帧稀缺与分布不平衡的问题。其次,设计多模态分割框架,通过双向膨胀注意力同时捕捉长时依赖和局部细节,并借助门控跨模态注意力引入文本信息,提升句子级视频边界学习的准确性。然后,提出基于不确定性和文本句子数约束的边界优化机制,有效缓解过分割和欠分割现象,进一步提升视频分割的准确性。最后,在多个公开数据集上验证了该方法的有效性:能够有效地检测长手语视频中的句子边界,实现句子级手语视频分割技术。
该项研究工作已被 The 33rd ACM International Conference on Multimedia(MM 2025,CCF-A类会议)录用。欢迎对该研究工作感兴趣的学术同行来信交流:yafeng@nju.edu.cn。


 English
English